


Kumo.AI has built an AI foundational model for relational database management systems (RDBMS). What does this mean?
AI foundation models are neural network frameworks, typically using transformer architectures, behind large language models (LLMs), which are trained on large and diverse unstructured datasets to perform generic tasks. They learn general patterns and representations from data, and can then be fine-tuned for specific application areas, like text generation and image recognition. In this, they are a “foundation” for building more specialized AI systems, because of their pre-training. Examples include BERT, GPT, or vision-language models like CLIP.
Kumo pitches itself as a foundation model designed for and trained on structured relational, table-based, datasets, such as those used in data warehouses. The company was founded in 2021 in Mountain View, CA, by CEO Vanja Josifovski, Chief Scientist and Stanford Professor Jure Leskovec, and Engineering Head Hema Raghavan. Leskovec and Josifovski worked at Pinterest while Raghavan had been an engineering lead at LinkedIn, IBM, and Yahoo.

Leskovec has stated: “To make predictions and business decisions, even the largest and most cutting-edge companies are using 20-year-old machine learning techniques on the enterprise data inside their data warehouses.”
These three have built a Relational Foundation Model (RFM), which can be fine-tuned on any specific relational dataset, such as a data warehouse, to understand natural language input and generate a response from that dataset to, for example, predict churn, identify fraudulent transactions, and make recommendations and predictions, in under a second. It eliminates the need to manually build and train separate models for each of these predictive tasks which can take months of effort.
KumoRFM is described in a scientific paper, “KumoRFM: A Foundation Model for In-Context Learning on Relational Data.” Leskovec was one of the five authors.
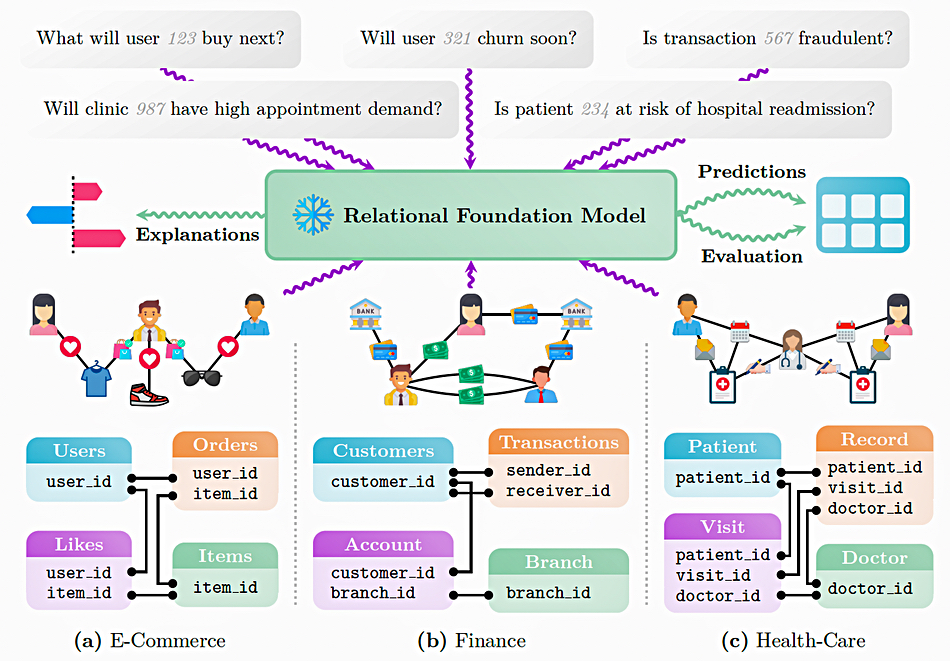
databases and schemas with highly varying structural characteristics, as found in (a) e-commerce, (b)
finance, or (c) health care. Secondly, they can be applied to any predictive task type, ranging from
one-off assessments (e.g. entity-level fraud prediction) to temporal predictive queries (e.g. temporal
recommendation prediction). Thirdly, they generalize to new predictive tasks and give accurate
predictions without any task-specific model tuning. Finally, not only do RFMs support prediction
outputs, but they also offer insights into the reasoning processes via explanations, and build trust
through extensive quantitative evaluation mechanisms
KumoRFM has a table-agnostic coding scheme, a Relational Graph Transformer, and is graph-based. It represents relational data as a temporal heterogeneous graph, where each entity is represented as a node, and the primary-foreign key links between entities define the edges. Trained customer staff can interact with it using Kumo’s PQL (Predictive Query Language) while non-technical users input natural language queries into a web console and these are then translated into PQL and executed. A Python SDK enables developers to integrate KumoRFM into a production workflow.
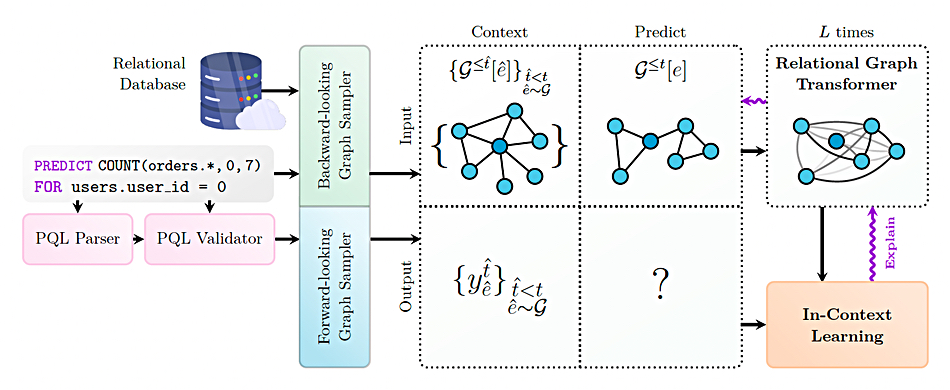
query, KumoRFM constructs context and prediction subgraphs by dynamically sampling from the
database: it uses a backward-looking graph sampler to obtain time-consistent context and prediction
subgraphs, and a forward-looking sampler to retrieve ground-truth labels. Context and prediction data
are then fed into a Relational Graph Transformer, which learns generalized subgraph representations
to enable in-context learning.
RFM can, the paper says, “seamlessly adapt to database schemas unseen during its training phase. This includes the ability to accommodate diverse structural characteristics, such as varying numbers of tables and different types of relationships (e.g., one-to-many, many-to-many).” It can handle a wide range of column types effectively, including columns that are proprietary or opaque, such as custom upstream embeddings or hashed identifiers” and “flexibly adapts to a spectrum of predictive tasks specified at inference time through a unified prompting interface. Not only are the predictions accurate; the model is able to perform them even for tasks it was never explicitly trained for.”
Kumo can be deployed in two ways:
- Kumo SaaS deployment provides an Apache Spark-based data platform, expanded support for more data warehouses, earlier feature access, faster bug fixes, and easier access to Kumo’s enterprise support tier.
- The Data Warehouse Native option allows you to bring your own data platform (Snowflake or Databricks) and access Kumo’s highly accurate predictions without raw data stored or materialized outside of your boundary. Data storage is always in your environment regardless of deployment option, and you can choose the deployment option that best aligns with your organization’s data governance policies and preferences.
Here’s a basic workflow:
- Connect your data: Set up a connection with your cloud data platform to grant Kumo access to your data. Or, upload files directly.
- Create tables and graph schema: Select training tables and connect them to create a graphical schema.
- Train a model: Define your predictive task using Kumo’s simple and intuitive Predictive Query Language, and let Kumo automatically train and optimize the model for your data.
- Run models: Run batch jobs to get embeddings or predictions on the latest data.
Have a look at a basic KumoRFM video here. For detailed information though, you should read the KumoRFM paper.
Comment
An alternative approach to analyzing relational data is to use knowledge graphs, with products from suppliers such as Illumex and Neo4j. Such graphs focus on the relationships between different data entities, modelling how pairs of items (entities) are related, and storing nodes and relationships instead of tables or documents.
Neo4j has integrated its product with Snowflake. It has a GraphRAG feature which combines knowledge graphs with LLMs. Neo4j supports vector embeddings and graph algorithms for analytics. Our understanding is that Neo4j needs users to define the graph schema and ingest data manually or programmatically, which is different from Kumo.
Illumex integrates with LLMs through its Generative Semantic Graph (GSF) that maps metadata from structured data sources. Users work with Illumex through tools like Illumex Omni, a chat interface, or semantic exploration features, where queries are mapped to the GSF for LLM responses.
Bootnote
Kumo is a Japanese word meaning cloud. There is no relationship between Kumo.AI and Kioxia’s now dead Kumoscale networked flash JBOF product.





