


Interview. Blocks and Files is a storage-focussed outlet that has progressed, with the industry, into data access, management and AI pipeline feeding. We know, as does everyone else, that organizations need a storage team as soon as the storage infrastructure grows beyond a certain point. The storage team provides stored data access and protection to applications that need it.
Analytics and AI is making data access far, far more complex. An analytics function needs its data located, filtered and selected, extracted, transformed, loaded and then processed with appropriately coded functions, SQL jobs for example. AI has only made this even more complicated with its initial reliance on files for training evolving to object data and retrieval-augmented generation for AI inferencing, vector databases and semantic search.
Data engineering and science teams have sprung up and they use different data concepts than storage teams. File and object data management supplier Komprise sits above the storage infrastructure and is involved in making stored data available and accessible to data teams. It says the two team types have dissonant concepts and need to talk.
We explored its ideas in an interview with Komprise President and COO Krishna Subramanian.
B&F: Isn’t it the case that, historically, customer organizations have always had a storage admin function responsible for ensuring the storage infrastructure operates properly and efficiently to store and provide access to the data the organization’s IT processes and users require? Do you think that a separate data platform team function has come into being? Why, and what are its responsibilities?

Krishna Subramanian: Yes, the storage team delivers the infrastructure to store and provide access to the data. But, “access to data” is a loaded word – and increasingly with AI, storage teams are simply ensuring the data can be accessed from the device whereas data engineering teams are the ones servicing AI teams, providing them with the data needed for their use cases. We believe storage teams can elevate their role in “providing access to the data” and partner more closely with data engineering and AI teams because at the scale of unstructured data, you cannot have data engineering teams who lack broad access to the data nor the right tools to organize the data for each use case. Storage teams who do have an organization-wide view of data should systematically provide approaches to rapidly classify and find the right data.
Also, as AI goes mainstream, you need a systematic, automated way for any user to profile, classify and pick the right data with proper data governance, which underscores the need for storage teams to elevate their roles. Data storage teams are evolving to become data services providers and this will require a closer relationship with the teams focused on how to derive greater value from the data that they manage and protect.
B&F: What are the advantages and disadvantages of having two separate teams? Why can’t one team do both jobs?
Krishna Subramanian: Historically, storage infrastructure teams have focused on delivering the infrastructure while data engineering teams have focused on data quality, data cleansing and serving the needs of data analysts and data scientists. So, storage teams focused on the technology and the use of data while data engineering focused on what’s in the data and how to get insights and value from it. This makes sense as manipulating structured data requires deep SQL expertise, which is the purview of data engineering teams and a different skill set than data storage management.
AI necessitates some tuning of this approach for two reasons: a) because AI relies on unstructured data which lacks a unifying schema and is not stored in SQL databases and spreadsheets, and b) AI is going to be used by everyone in the enterprise so storage teams who have access to and management responsibilities for all the data should play a bigger role in providing tools and processes to classify the data, find the right data sets, tag sensitive data, etc. Essentially, the two separate teams are still needed but greater collaboration between the two is necessary due to unstructured data and AI. Ultimately a new set of SLAs and KPIs will emerge and CIOs may create new org structures to address these emerging use cases and requirements.
B&F: Is the data team’s area of responsibility restricted to AI? If not, where does it stop? Does it represent the needs of all data access users and processes to the storage team?
Krishna Subramanian: Data engineering teams were traditionally focused on data analytics processing and are now expanding their role to delivering AI services. Many organizations also have data scientists, departmental IT, and other roles that help users get access to data. The dramatic shift that AI brings is the democratization of data re-use. While historically, analytics teams were the ones reusing data, now every user may need to feed the data they can access to AI. So, getting the right data to the right AI use case should be standardized for every user with automated data governance.
B&F: Will storage teams need to evolve from infrastructure maintenance into data service providers to help data analytics teams as they gather the requirements and design processes for AI. What skills will they need for this?
Krishna Subramanian: Yes absolutely. Storage teams should think about how they work with departments to profile and enrich metadata to make it easier to curate data for projects. Learning how to provision and manage GPU-ready infrastructure and the data lifecycle to balance cost, performance and security is another skillset. At the same time, they will need to enforce governance to safeguard sensitive information, ensuring compliance with regulations and preventing leaks into commercial AI models. So the storage admin/engineer role is changing, and becoming much broader vis a vis AI, data preparation and data governance.
B&F: Will data platform teams need to build common metadata definitions with storage teams and collaborate on an inclusive data governance strategy incorporating unstructured data?
Krishna Subramanian: Yes. Data teams, storage teams, security and compliance teams and data owners should collaborate on common metadata definitions, sensitive data labels and a data governance strategy.
B&F: Won’t each team have its own metadata? Can you provide an example of common metadata definitions?
Krishna Subramanian: Yes, there will be both. Common metadata definitions include things like sensitive data labels aka PII, IP and employee IDs, author information, project codes or grant numbers. SIDs (security-identifier) can be very useful in M&A scenarios and to enforce compliance. Storage teams can also help with extraction of latent metadata that is outside of the filesystem such as header metadata and application-generated metadata.
B&F: Are you seeing a role for Komprise as an interface layer or function between the storage and data teams, helping represent each to the other? How would that work?
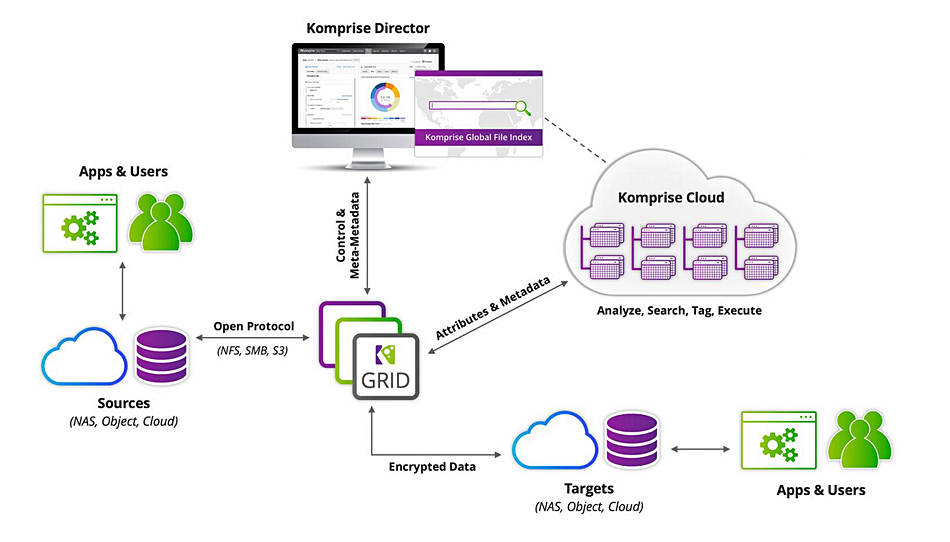
Krishna Subramanian: Absolutely. Komprise provides a single place to search across all enterprise unstructured data and it provides ways to continually enrich that data. Komprise has role-based access so data owners and data engineers can view the data they have access to and do things like tag and search data with Komprise Deep Analytics. Storage administrators can move data, govern data usage and execute data workflows systematically through Komprise Smart Data Workflows. Komprise provides a common interface through which data teams and storage teams can interact.
B&F: Do you have any customer examples of customers having two separate teams? How do they work?
Krishna Subramanian: One of the world’s largest cancer research hospitals uses Komprise to achieve collaboration across their data teams and storage teams. The data teams use Komprise to tag data associated with each research project. When a project is complete, files are automatically tiered based on policies the storage administrator set in Komprise. This customer has saved millions of dollars using this approach of collaborating effectively between departments and storage IT via Komprise.
Another example is an oil and gas customer that recently went through a divestiture. The company’s compliance team used Komprise to segregate the data for each entity based on the compliance teams selecting the SIDs they wanted mapped to each entity and storage IT executing the data migrations via Komprise.





