


Interview. Liqid has announced composability products enabling host server apps to access dynamically-orchestrated GPU server systems built from pools of GPU, memory, and storage, focused on AI inferencing and agents, with its v3.6 product release. The apps support both PCIe-linked system components and CXL-accessed memory.
We talked with CEO Edgar Masri, President, Chief Strategy Officer and co-founder CMO Sumit Puri, and Dave Larson, GM and CTO, IO Acceleration Business, to explore the company’s technology capabilities and understand how they would be used. Their words have been edited for brevity and continuity. Let’s set the scene by refreshing our view of the product elements in Liqid’s recent announcement;

B&F: Who is your competition?

Edgar Masri: Our biggest competition is still the status quo and people buying servers for four or five, six GPUs and then being stuck growing beyond that.
Sumit Puri: There is a massive swing in the industry right now towards high powered GPUs. The entire Nvidia portfolio is on the PCIe side going a minimum of 600 watts per device and everything is shifting towards high-power stuff. So our first product is our PCIe 10-slot expansion chassis [EX-5510P] that we use in our composable architecture. One of the key benefits is the 600-watt support.
And that is a critical thing. If we take a look at the server vendors, the Ciscos, the Dells, the guys that are out there in their entire portfolio. Dell as an example, has one server today that supports 600 watts. That’s their new 4RU box; the XE7745 that can support 600 watt devices. The balance of their portfolio, their 1, their 2RU boxes: none of them can support these new devices. And so we think that’s a big gap in the industry that we can help fulfil with this new piece of hardware.
It is better than anything else available in the market. It has things like redundant power supplies from serviceable fans; it has multiple management ports. All the enterprise bells and whistles that you could want in a product like this have been built into it.
This box is built by Accton. Accton is a multi-billion dollar, publicly-traded technology company in Taiwan where Edgar was the CEO prior to coming here. And so we are extremely lucky to have not only Edgar but his relationship with Accton.

We have an early OEM partner who’s been working with us on this product for a couple of years and that is Fujitsu. Fujitsu takes our product and white labels it or private labels it in Japan on the hardware, on the software they put the Fujitsu logo on it. Edgar at Accton had a good relationship with the Fujitsu team, so it just all continues to move forward together.
[The EX-5510C CXL 2.0 chasssis] holds 20 terabytes of DRAM per box and, just like our composable GPU solution, we will have trays or resource pools of DRAM. We’ll be able to connect those to multiple servers. We will use our Matrix software and we will allocate resources to servers on the fly.
The days of talking about CXL are over and what we like to say is: Liqid is going to be the company to deliver the full stack. And what we mean by full stack is, not only the expansion chassis, but the switching layer to go with it so that we can build big clusters. And also the fabric manager, which is our secret sauce, Liqid Matrix, that’ll be part of the solution, in addition to all the ancillary things like optical interconnect.
We are leading the market in this segment and we think there’s going to be some really interesting use cases around database, around in-memory database, around RAG acceleration, where now large pools of memory are going to make an impact.
Liqid Matrix is our fabric manager and the things that we’re touting on this release is number one, our ability to do multi fabric. So speak to a pool of GPUs, speak to a pool of memory, manage all of that with a single pane of glass. And so all of the million lines of code that we have written over the years to make our PCIe magic work, we get to bring that over to CXL. And now with a single piece of software, we can orchestrate the data center as [the slide below] shows. Our vision is, at the end of the day, the data center will be disaggregated. We’ll pull GPU resources, PCIe resources, DPU resources over our PCIe fabric.
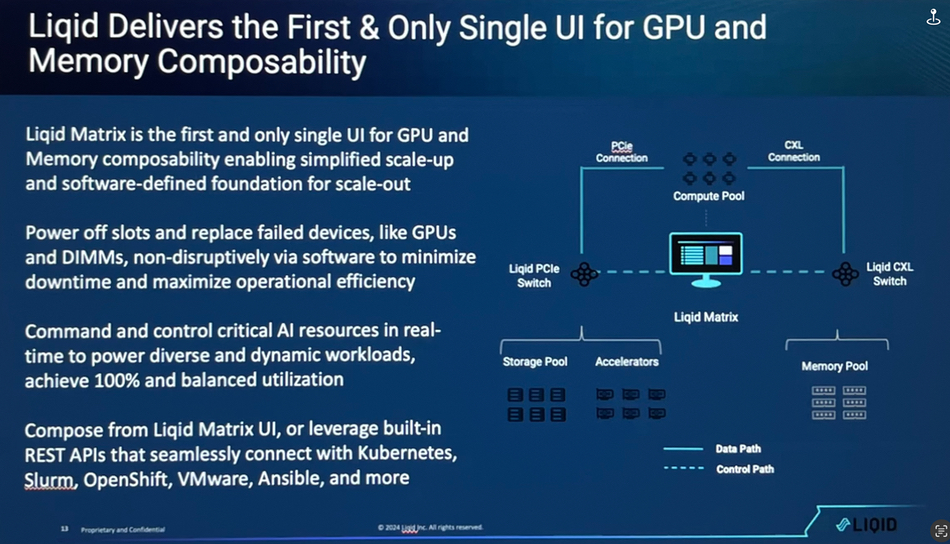
We will pull DRAM resources over CXL today. There will be DRAM-enabled SSDs, DRAM-enabled GPUs at some point in the future. Our vision of the software has always been multi-fabric and we scale up with these current technologies like CXL. In the future, there may be UALink and those other things, but then we also have a very clean easy path to be able to integrate things like Ethernet technology because, eventually, when we grow beyond the box, we want to be able to scale out over those legacy Ethernet [and] Infiniband architectures. Our solution, because we’re in a very standard space, fits very well into a paradigm where people are already running Ethernet, InfiniBand in the data center. We can plug our pods in. And that leads to the next big announcement, which is around the software piece, which is around Kubernetes. In addition to promoting our multi-fabric orchestration capability in this 3.6 release, we have a huge focus on Kubernetes orchestration.
If you recall a few years ago we introduced our Slurm integration and we had big universities … where they were using Slurm as the orchestration engine. As part of orchestrating with Slurm, they would put a config file out there that said, hey, with this job I need four servers with two GPUs apiece and this amount of storage. And we’d go on the backend and we would create bare metal infrastructure based upon the Slurm orchestration engine. Now our next move is into Kubernetes. We think Kubernetes is the killer app for composability. The entire enterprise is using containerized methodologies for deploying their workloads.
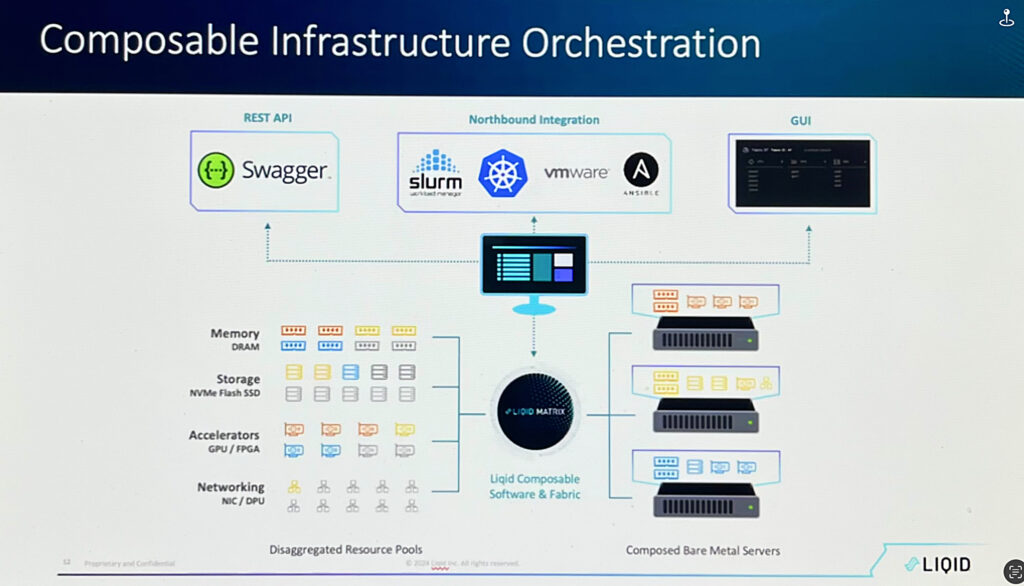
97 percent of enterprise customers are using containers. Nvidia has made a statement that said, if you want to go do inference, you must use containers. Containers are built for ease of deployment, ease of serviceability, ease of scaling. They’re moving in that direction. We, in this software release, have introduced our Kubernetes plug-in. So the simple way of describing this is, when you are deploying a Kubernetes pod in your environment, you don’t need to know anything about composability, you don’t need to know anything about orchestration, you don’t need to know anything about the way disaggregation works. All you need to do is with that Kubernetes pod provide a very simple spec file and the spec file has just a couple of inputs. This is the model that I want to run. These are the GPUs I want to use, this is how many of them I want, and this is the server that I want you to go deploy it on.
We automate the entirety of deploying AI in the backend. We refer to it as one-click deployment of inference. You come in and say, give me Llama-7B, go, and we will create the entire backend model with the appropriate GPUs and the appropriate server and we will give back to the user a running instance of any model that they want and we will have automated the entire backend process. So you don’t need to know anything about orchestration composability. The only thing you need to know is how to run your Kubernetes environment. But now we will make it dynamic and, at the end of the day, very efficient.
B&F: Do you support x86 CPUs in this?
Sumit Puri: Yes. So we support the full gamut; Intel, AMD and Arm.
B&F: And have you linked to external storage?
Sumit Puri: Yes. Two ways that we do storage. And so one way we do storage is, as you know, we have our IOA product which Dave champions for us, that is our Honey Badger product. Very, very, very fast IO; the fastest storage on the planet. It’s going up to 128 TB per card now. And that is local storage we deploy in the kit. And so I would say 70 plus percent of our deployments include that card, for very fast cache in and out of the GPUs as an example. And then the other way we connect to storage and the architecture; the server will have a legacy Ethernet, InfiniBand, IP network to the data centre and you can go grab your VAST Data, your WEKA IO, your legacy storage over your Ethernet connection.
B&F: And if there’s going to be some kind of GPU Direct connection from the GPUs to the external storage that’s supported as well?
Sumit Puri: That is supported as well. We would argue that running GPU Direct storage to that Honey Badger card in the box is the best way to do it. There’s no better way than putting the GPU four inches physically away and turning the RDMA capability on. So yes, we support both ways.
B&F: I’m thinking that what you’ve got here is hot data storage in the LQT 5500. That needs to be loaded from someplace and that’s obviously, to my mind, from external storage.

Dave Larson: Yes. And this device, the expansion enclosure, is PCI Gen five. You can populate an RDMA nick, a high performance nick for an RDMA connectivity to a much larger NVME or frankly spinning if you want it. If you want spinning disc, it’s fine. And then you populate the hot store locally. And then of course in a combined environment, which we’re not talking a lot about, but you then have even hotter store but also ephemeral store in CXL memory.
The main thing and the main benefit, this is the difference in bandwidth and more importantly latency we’re talking about it’s one to two orders of magnitude better latency on CXL DDR4 than NVMe [PCie] Gen5 by 16. Right? And then you have another two orders of magnitude latency to the far memory in a dual socket, and then you have another order of magnitude to the near socket memory. So there are four tiers of memory speed that people can leverage appropriately for how you deploy the information and the weights and everything else into the GPUs for an AI infrastructure
B&F: Can you mix different types of GPU inside one of these 5510P chassis?
Sumit Puri: Yes, absolutely. So not only can we mix different type of Nvidia GPUs, but we can also mix Intel and AMD, all the different varieties, into the box.
And not only do we support GPUs in the box, we are seeing customers begin to use FPGAs and other DPU type devices in the box. [There’s] a really important FinTech customer who finds benefit in deploying FPGAs in our box, not only for the latency benefit, not only for the fact that they can deploy 10 or 30 at a time, however many that they need through our software, they’re actually able to reprogram the device dynamically.
So depending on what they are trying to do, they can change the personality of the FPGA, reset the FPGA, because one of the new capabilities of this new chassis is that we can power cycle that slot remotely. And so as you’re doing things like FPGA reprogramming, you don’t have to walk over and enable the physical reboot of the server. All of that mess goes away. And so there’s new devices that are being put into our system and FPGA is actually a hot one now.
B&F: What areas would be a good fit for using your kit?
Sumit Puri: One of the areas where we are finding some success is edge environments. And those slide five Joe. So edge is really interesting for us. Think about data, think about GPUs. All the data is created at the edge and so customers either have to do one of two things, move that data into the core data centre or move the GPUs to the edge.
What is the problem with edge? Edge is extremely limited on power. We don’t have a hundred kilowatt racks that we can run at the edge. We’ll be lucky if we find a 17 kilowatt rack at the edge. And so when you look at a 17 kilowatt rack and you say, how am I going to deploy AI into that rack? And we speak up this concept of tokens per watt, tokens per dollar, I got a limited amount of power. How many AI tokens can I squeeze out of that limited amount of power? This is an example of the kinds of things our customers are looking at. I can go and I can buy a single DGX solution and it’s the eight way NV link Ferrari kind of thing and it’s a big monolithic block of infrastructure and that block of infrastructure will consume 1213 kilowatts of power.
Or we can deploy a Liqid-type architecture where we can choose lower power GPUs. Remember H100 comes in two flavours. It comes in a high power NVLink flavour, which is the top tier, which is what you need for things like training or it comes in a lower power PCIe variant, a much lower power PCIe variant, which is great for things like inference.

So in these kinds of use cases where power is very limited, we can do architectures [see slide above] on the right where in that same power budget we can squeeze 30 GPUs instead of eight GPUs. We can put two compute nodes instead of one compute node. And I’ll argue that the amount of tokens, the amount of capability is far greater for things like inference on the right hand side [of the slide above] than putting one large big monolithic block out there. And so think of telcos, think of CDN, think of edge providers who are looking to deploy GPUs into these power-sensitive environments. That’s an area, as an example, where we’re finding success.
B&F: The edge to my mind spans a very large range of applications; from small shops point of sale systems right up to small data centres. I think you’re talking more about the small data centre area.
Sumit Puri: Correct. We are not talking the deep, deep edge where we’re talking about the refrigerator. No one cares about that, right? We absolutely care about the close edge, which is yes, I’m a small data centre servicing a bunch of regional edge points. We have had discussions with retail customers around do we put some of this infrastructure, for example, inside of something like a Walmart where there’s tons of camera feeds and the number of cameras varies per store. So having some kind of flexible architecture here could be a benefit. It is probably not going to go in that direction. I think it’s the small regional data centre where you’re limited to 10 – 20 kilowatt racks as the common thing servicing a bunch of edge end points. That’s where we see ourselves landing.
B&F: You are going to have AI applications running at the edge that previously or currently are simply not possible?
Sumit Puri: The market itself is bifurcating here. There is going to be two sets of customers. There is going to be customers who do training, and if you are OpenAI and you are Meta and you are a handful of government agencies, yeah, go buy the SuperPod architecture, spend $50, $60 million, build dedicated data centres. That’s not the problem we’re trying to solve. We’re solving the problem for the rest of the world; the commercials, the enterprises. Higher education is probably our single most successful vertical. We find a tremendous amount of opportunity in higher ed. Think about higher ed and research for a second. Different students bringing different workloads to the supercomputer. Different workloads need different T-shirt sizes. We integrate with things like Slurm where we can match the T-shirt size to the workload. And so we are well on our way to having dozens of universities deploy our solution.
B&F: It is clear to me that you’ve got a stack of funding and you’ve been working for a long time because developing hardware and software like this is not cheap and it’s not quick either. So I should start thinking of you as a mature startup with relatively mature technology and serious customers. We’re not talking about some back of a garage operation here hanging on by its shirt sleeves.
Dave Larson: You are correct. You should think of us this way; we’ve been around for a little while. We are expert. We are the most expert place for PCIe composability architecture, and we have more than a hundred patents that have been granted to us in this area throughout our work, and they’re foundational to PCIe, composability and CXL.
B&F: I’m assuming that when CXL 3 comes along and PCIe 6 comes along, you’ll be leading the way there too.
Sumit Puri: That is absolutely the plan. A hundred percent.
B&F: It’s my impression that HPE was early into the composability area, but to be blunt, I think it’s failed.
Dave Larson: I feel like you were looking at my LinkedIn. I was at HPE for seven years. Most recently, four or five years ago, I was in the CTO office reporting to Mark Potter and I was the chief technologist for data centre networking, data security and cloud architecture, and I worked very closely with the composability team. A lot of my friends are still there, with Synergy and Virtual Connect and all the things that they built about composability. They had a very nice ring to it. Unfortunately, what you found is their largest customers that deployed Synergy deployed it statically in monolithic architectures. They never took advantage of the composability. They just paid the premium for all the flexibility and didn’t use it. So there’s a bit of maybe an internal backlash over there because they were the loudest voice for composability.
What we have here is actual composability, right? And I say that and I tell my friends who are in HPE, the same thing, and they struggle to believe the story because they’ve lived it unsuccessfully. But as we continue to show our capabilities, particularly on CXL, we’re quite certain that we’re going to get their attention back, because CXL composability is something that is central to what they do. Their Superdome servers have always had that kind of capability at a very, very, very premium price. We deliver that for industry standard servers at a much, much lower price point for people to get into that business.
Bootnote
The interview mentioned Fujitsu as a Liqid partner and it is also partnering with Dell, Cisco, Samsung, and Supermicro.





